例えば
data Q1;
do X=1,3,5;
output;
end;
run;
proc sort data=Q1;
by X;
run;

data Q2;
do X=2,4,6;
output;
end;
run;
proc sort data=Q2;
by X;
run;

のようにソート変数の一致したデータセットが複数存在する場合
data A1;
set Q1
Q2;
by X;
run;
とすると、以下のように

全てのデータセットを縦結合してからソートしなおす必要なく、ソートされた縦結合データセットが
得られるという技術のことです。
特に巨大なデータセットの場合、巨大なやつをつくってからproc sortするよりも、
小さい部品となるデータセットごとにソートしておいてインタリーブした方が、処理効率が
よいらしいです。
で今回のメインは処理効率の話ではなく
インタリーブをつかってSQL再マージと同様の自己参照処理をやってみようという話です。
SQL再マージ?という方はSAS忘備録の「SQL「再マージ」入門」を先に読んでください
http://sas-boubi.blogspot.jp/2013/12/sql_26.html
今、以下のデータセットがあったとします。
data Q3;
X='い';Y=1;output;
X='い';Y=5;output;
X='い';Y=9;output;
X='ろ';Y=2;output;
X='ろ';Y=3;output;
X='は';Y=2;output;
X='は';Y=4;output;
X='は';Y=6;output;
run;
proc sort data=Q3;
by X;
run;

今、以下のデータセットがあったとします。
data Q3;
X='い';Y=1;output;
X='い';Y=5;output;
X='い';Y=9;output;
X='ろ';Y=2;output;
X='ろ';Y=3;output;
X='は';Y=2;output;
X='は';Y=4;output;
X='は';Y=6;output;
run;
proc sort data=Q3;
by X;
run;
このデータセットに対して、もとのX,Yはそのままに、Xの値ごとのYの合計を一体化させたデータセットを作成したいとします。
つまり
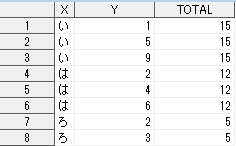
上記の感じです。
SQL再マージで書くなら
proc sql noprint;
create table A0 as
select X,Y,sum(Y) as TOTAL
from Q3
group by X;
quit;
で詰みですね。
あるいはdo untilによる複数データステップの併合を利用して
data A00;
do until(last.X);
set Q3;
by X;
retain TOTAL;
if first.X then TOTAL=.;
TOTAL+Y;
end;
do until(last.X);
set Q3;
by X;
output;
end;
run;
でも同じ結果になります。
【参考】do until(end変数)set end=を利用して、複数のデータステップを1つにまとめて共存させる方法
http://sas-tumesas.blogspot.jp/2013/12/do-untilendset-end1.html
ぱっと思いつきませんでしたが、call executeでもかけそうです。
脱線しました、他の方法を考えていると、きりがないです。
インタリーブで書くと、以下のようになります。
data A2;
set Q3(in=in1)
Q3;
by X;
retain TOTAL;
if in1 then do;
if first.X then TOTAL = .;
TOTAL = sum(TOTAL,Y, 0);
end;
else do;
output;
end;
run;
で詰みです。
ポイントは、setで敢えて元データを倍加重複させておいた上でインタリーブしてるところですね。
で、そのままだといけないので、in=で要約統計を出す部分と、実出力部分を分けているのですね。
タネさえ解れば、どうってことない処理ですね
0 件のコメント:
コメントを投稿