僕が知っているのは「私の戦闘力は53万です」ですげーっ!!て時代だったんで、そんなジンバブエドルみたいな単位になってるとは知りませんでした
しかし、スカウターみたいな便利なものがあればいいですが(よく爆発するけど)、強さといった複合的要因でなりたっているものをスコア化するのはなかなか難しいです。
また、普段からスカウター慣れしていないと算出された戦闘力の差が、どの程度ならどのくらい勝てるかいうことが実感できないです。
(正確な値だしているのに、ちっ壊れてやがる!グシャっていうシーンあった気もするけど、慣れすぎているが故の弊害でしょうね)
そういう実際の能力を数値化する方法と違うアプローチとして、測定対象の対戦結果データがある程度存在する場合、強さ(勝率と捉える)が正規分布に従うと仮定し、数値化した値の差から勝率が逆算できるように作られたイロレーティングというものがあります。
原理など詳しくはwikiや参考ページなど検索してみてください。
【wikipedia】
https://ja.wikipedia.org/wiki/%E3%82%A4%E3%83%AD%E3%83%AC%E3%83%BC%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0
【ヘキサドライブ(ゲーム会社)公式ブログ】
http://hexadrive.sblo.jp/article/67433861.html
イロレーティングの肝となるのは以下三点。
・ゲームの結果は一方の勝ち、一方の負けのみとし、引き分けは考慮しない(0.5勝0.5敗と扱うものとする)。
・200点のレート差がある対局者間では、レートの高い側が約76パーセントの確率で勝利する。
・平均的な対局者のレートを1500とする。
特に2点目、レーティングの差から、仮に相手を見たこともなくても勝率が推定できるという
のがいいんです。
もともとチェスで運用されていたもので、今はネット将棋、囲碁など主たるサイトはこれを基本にそれぞれカスタマイズして使ってユーザーの実力を測り、対戦マッチング等に利用しています。
僕もネット将棋やるのですが、これが結構よくできてるなぁって実感します。
実際、後で自分の対戦成績と対戦相手のレーティングで集計してみると200差の相手には
3割勝ててないですし、レーティングで100あいてると、やっててもちょっと自分より強いなって感覚を持ちます
算出法はいたって簡単、何局か後でまとめて計算するのと都度計算するので多少ロジック代わりますが、
プレイヤー1のレーティングがrate1、プレーヤー2がrate2とすると
プレイヤー1が勝利する確率e1は以下で算出できます
e1 = 1/( 1 + 10 ** ((rate2-rate1)/400) );
そして、対局後のレーティングは,
勝利の場合S=1 敗北はS=0 引き分けはS=0.5として
対局後のレーティング = 現在のレーティング + 16 * ( S - e1);
16は定数で、プロなら16、アマなら32にすると安定するといわれています
例えば以下のように現在のレーティングデータと
data Rating;
length name $10.;
input name rate;
cards;
A 1500
B 1500
C 1500
D 1500
;
run;

時系列に並んだ対局結果のデータセットがあった場合
(1はプレイヤー1が勝者、2は2が勝者、3は引き分け)
data hosi;
length player1 player2 $10.;
input player1 player2 win;
winner=choosec(win,player1,player2,'引き分け');
cards;
A B 1
B A 2
D A 2
B C 1
C B 2
B D 1
D B 1
A C 1
A D 1
C D 3
D C 1
C A 2
D C 1
C D 2
B C 1
;
run;

コードは
data cal;
if _N_=0 then set rating;
if _N_=1 then do;
declare hash h1(dataset:'rating',ordered:'Y');
h1.definekey('name');
h1.definedata('name','rate');
h1.definedone();
end;
set hosi end=eof;
if h1.check(key:player1) ne 0 then do;
h1.add(key:player1,data:player1,data:1500);
end;
if h1.check(key:player2) ne 0 then do;
h1.add(key:player2,data:player2,data:1500);
end;
h1.find(key:player1);
rate1=rate;
h1.find(key:player2);
rate2=rate;
e1 = 1/( 1 + 10 ** ((rate2-rate1)/400) );
e2 = 1/( 1 + 10 ** ((rate1-rate2)/400) );
rate1 = rate1 + 16*(ifn(win=1,1,ifn(win=3,0.5,0)) - e1);
rate2 = rate2 + 16*(ifn(win=2,1,ifn(win=3,0.5,0)) - e2);
h1.replace(key:player1,data:player1,data:rate1);
h1.replace(key:player2,data:player2,data:rate2);
h1.output(dataset:cats('rating',_N_));
run;
とすれば、1対局ごとのレーティングの状態をデータセット化できます
(わかりやすくするために1局ごとに作ってますが、普通はif eofで最後の
時だけratingのデータセットを吐けばいいです)
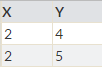
1局目、A対BでAが勝利した後のデータセットをみてみると、
このようにAが少しあがり、Bが少し下がります。

最終的に全対局後をみると以下のようになり

全勝のAと全敗のCでは100ほど開いています。
100だと勝率64%ぐらいです
ある程度データがたまらないと安定したレーティングは得られませんが
まあ、AとCが戦ったら6割5分Aが勝ちそうだというのは感覚的に納得できます
ちなみに式をみればわかりやすいですが、レーティング差が大きい相手との
対局ほど、移動するレーティングが大きくなります。
雑魚に負けた方はレーティングが大きく下がり、下克上した方は大きく上がります。
わかりやすいですね。
イロレーティングの改良法については色々研究されているみたいなので興味のある方はぜひ
勉強してみてください