を作れと言われたら、第一感で浮かぶのは
data A1;
do X=1 to 10;
if mod(X,2)=1 then output;
end;
run;
こんな感じのコードではないでしょうか?
ループをまわして、条件に合った時のみ処理するというのは、自然な発想だと思います。
でも敢えて逆に考えてみます。
余りが1の時に処理するのではなく、余りが0の時に処理しないというように考えてみます。
すると
data A2;
do X=1 to 10;
if mod(X,2)=0 then continue;
output;
end;
run;
こうなります。
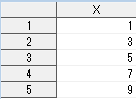
結果は同じです。
この発想の方が、プログラムが自然にかける時もあるので、覚えておいて損はないはずです。
ちなみに、continueとleaveは同違うのかというと、continueがスルーしてループを継続するのに対して、leaveはその時点で、ループを打ち切ります。
なので
data A3;
do X=1 to 10;
if mod(X,2)=0 then leave;
output;
end;
run;
すると

ってなっちゃいます。



