data Q1;
length X Y Z $10.;
X='ABC';Y='ACC';Z='ABC';output;
X='BBC';Y='BBC';Z='BBC';output;
X='CBC';Y='CBC';Z='CBB';output;
run;

Xの値とYの値、Xの値とZの値、Yの値とZの値を比較して同一かどうかを検証
したいとします。
方法はたくさんありますが、たとえば、compare関数を使えば
data A1;
set Q1;
XvsY=compare(X,Y);
XvsZ=compare(X,Z);
YvsZ=compare(Y,Z);
run;

のようになり、0であれば同一、数字は最初に差異が発見された位置を示しています
data A2;
set Q1;
YvsX=compare(Y,X);
ZvsX=compare(Z,X);
ZvsY=compare(Z,Y);
run;
のように指定をひっくり返すと

基準が逆転するので正負も逆転します。
で、こういうことをcompareプロシジャでやってみたい場合は
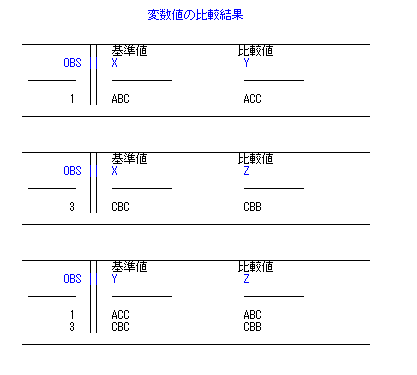
proc compare data=Q1;
var X X Y;
with Y Z Z;
run;
のようにvarとwithの指定順を同期させることで可能です。縦に見ると、何と何を比較しているか
わかりやすいです。
結果の抜粋は以下です。
ODSへの対応や、差異のデータセットへの吐き出しについてcompareプロシジャには
まだ改良の余地があると思うので、次期バージョンでもいいからてこ入れして欲しいなと思います。





