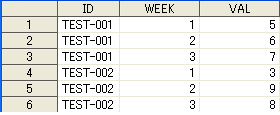
data Q1;
X='い';Y=1;Z='A';W=1;output;
X='い';Y=2;Z='B';W=1;output;
X='い';Y=3;Z='C';W=2;output;
X='は';Y=4;Z='D';W=2;output;
X='は';Y=5;Z='E';W=.;output;
X='ろ';Y=6;Z='E';W=3;output;
run;
proc sort data=Q1;
by X;
run;

を使って

のようにXを起点にしてその他の変数を全て転置したデータセットを作成せよと言われたらどうしますか?
多分、すぐに思いつくのが
proc transpose data=Q1 out=_Y(keep=X Y_:) prefix=Y_;
var Y;
by X;
run;
proc transpose data=Q1 out=_Z(keep=X Z_:) prefix=Z_;
var Z;
by X;
run;
proc transpose data=Q1 out=_W(keep=X W_:) prefix=W_;
var W;
by X;
run;
data A0;
merge _Y _Z _W;
by X;
run;
だと思います。
ただし、この方法だと、転置する変数分だけtransposeを書くため、どうしても処理に無駄があるように僕はずっと感じてきました。
特に以前、仕事で、臨床検査値と臨床検査基準値を、検査日と基準値適応開始日を比較しながらマージすることが多かったため、その過程で上記のコードをよく書いていたため、もっと改良できないかと常に思っていました。
それに対する一つの答えが、今年ユーザー総会で発表したハッシュオブジェクトに関する論文で、ハッシュオブジェクトを利用することで、そもそも上記のようなデータセット加工を行わずに、ダイレクトにマッチングができるという内容でした。
それで少しは気が晴れたのですが、それはあくまで、連続transposeと再マージ処理を避けるテクニックなので、まだひっかかりがありました。
そこで今回、2ステップにはなりましたがdo untilの終了条件にlast.変数を使う特殊なループ法でやってみました。
ちなみにこのループ法、海外ではDow loopと呼ばれていて、「SAS dow loop」で検索すると、その応用法がたくさんでてきます。
Dowの「w」の文字はIan Whitlockという方の名前からつけられました。2000年にこの方が、初めてSAS-Lというコミュニティで、この方法を発表し、それがあまりに画期的であったため、リスペクトを込めて、ループの終了条件にfirstやlast等を使用するような変則ループ全般をDOWループと呼ぶようになったそうです。いい話だな~、うらやましいなぁ。
僕はa matsuさんにこのブログのコメントで初めDowの書き方を教えていただきました。
さて、前置きが長くなりましたが、コードです。
proc sql noprint;
select max(A)into:TNMAX from
(select count(*) as A from Q1 group by X);
quit;
data A1;
informat X Y_: Z_: W_:;
array Y_(&TNMAX) 8. ;
array Z_(&TNMAX) $2.;
array W_(&TNMAX) 8. ;
do until(last.X);
set Q1;
by X;
if first.X then i=0;
i+1;
Y_{i}=Y;
Z_{i}=Z;
W_{i}=W;
end;
drop Y Z W i;
run;
で、結果は先述の通りになります。
まあ、満足。
ただ、まだ、もうちょっと面白い手順があるんじゃないかと思うのでもう少し考えてみます。
SASのデータステップについて深く勉強すると、思いついた面白い構想や、突飛なアイデアを強引に実現できる力がついてきて、結局それがモチベーションになってきてる気がします。