SAS9.4から、SASの中でDS2という新しいSASのオリジナル言語が使用できるようになりました。
SAS9.4が未導入のところで働いていたので、DS2言語、気にはなっていたけども全く手を付けていませんでした。(9.4もう入れているとこってどれぐらいあるのかなぁ?)
商用利用はできませんが、SAS Univercityだと最新のSAS9.4が搭載されているので、今日初めてDS2でプログラミングしてみました。
またいずれ、きちんと勉強した後で、基本から解説する記事を書きたいと思います。
まだ、 僕自身全然わかっていないので、間違っている場合はご指摘ください。
DS2はSAS Technical news 2013 Winterでは
「
DS2 とは、Base SAS 9.4で提供される新しいデータ操作言語です。DS2は、処理のパッケージ化、FedSQL の呼び出し、マルチスレッドによる並行処理など、従来の DATA ステップを拡張した機能をサポートしており、高度なデータ操作を行うことが可能です。」
と説明されていました。
まあ、何言ってるかよくわかんないですけど、とりあえず、今までのデータステップでは無理だったことが、拡張されてできるようになったよ!ってことみたいなので
今回は、1つのステップの中で、データステップと、SQL(正確にはFedSQL)とハッシュオブジェクトを組み合わせて、使用するという、ちょっとした変態コードを書いてみました。
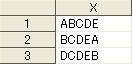
まずは2つのデータセット
data Q1;
X='い';Y=1;output;
X='い';Y=2;output;
X='い';Y=3;output;
X='ろ';Y=3;output;
X='ろ';Y=2;output;
X='ろ';Y=4;output;
X='は';Y=4;output;
run;
data Q2;
Y=1;Z='A';output;
Y=2;Z='B';output;
Y=3;Z='C';output;
Y=4;Z='D';output;
run;
があったとします。
そこで、今回、Q1のXごとにYの平均値をだし、その値をキーとして、Q2のZを取得し、XとZを連結した文字列を作る処理がしたいとします。
工程を書き出すと、
①:Q1をSQLを使って集計する
②:Q2をハッシュオブジェクトに入れる
③:①で集計されたデータセットを使い、②のハッシュオブジェクトからZをfindメソッドで取り出してXとcats関数でくっつける
となります。
これをDS2で書くと
proc ds2;
package hash /ext='hash' overwrite=yes; run;
data A1(overwrite=yes);
declare package hash hq2(0,'Q2');
declare char(10) X;
declare double Y;
declare char(10) Z;
declare char(20) XZ;
method init();
hq2.defineKey('Y');
hq2.defineData('Z');
hq2.defineDone();
end;
method run();
set { select X,mean(Y) as Y from Q1 group by X };
hq2.find();
XZ=cats(X,Z);
end;
enddata;
run;
quit;
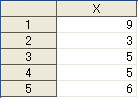
で結果は
となります。
なんとまあ不思議なコードですよね、部分的にはデータステップまんまだし、
SQLまんまだし、ハッシュオブジェクトまんまだし。
簡単に説明(多分、間違いが含まれているので信用しない)。
DS2でハッシュ使おうと思ったら、パッケージていうので定義する必要があるんですね。
このパッケージ化という概念がどうやらDS2のポイントになってるみたいですが、それはまた今度までにちゃんと勉強して整理しておきます。
ハッシュパッケージの宣言部分は今までのハッシュオブジェクトと大体同じですね。
ただし、そこを method init(); end;でくくっているんですが、これがね、決まり文句で、今まで
if _N_=1 then dol; end;で処理の最初だけ1度実行というデータステップの書き方に対応してるんです。
で
method run(); end; で括っているところが、これも決まり文句で、今まで普通のデータステップとして処理していた部分の書き方、つまり1obsをPDVに持ってきて処理してoutputって部分に該当するみたいです。
で
set { select X,mean(Y) as Y from Q1 group by X }; の部分ですが、
なんか、今までのSASの常識からすると、ふざけてんのかって感じで、初心者がかいちゃいそうなコードですが、DS2ではこれがまかり通っちゃうんですね~
sqlの抽出結果がそのままデータセットとみなされてsetの対象になっています。
おっさんにはついてけないですよ
hq2.find(); と XZ=cats(X,Z); の部分はそのまんまですね。
さて、さらっと説明しましたが、DS2の凄さは全然こんなもんじゃないです。
サンプルなどを検索してもらえばわかりますが、なんか処理の中にfcmpプロシジャを突っ込んだようなことができて、まあ要は処理のパッケージ化なんですね。
なんだか印象としては、データステップとSQLとハッシュオブジェクトやらマクロやらユーザー定義関数の機能を、ミキサーかけて、煮込みましたみたいな感じをうけました。
先述のTechnical newsでは、DS2導入のメリットとして「複数の箇所で使用される処理のコードを一箇所で集約することで、プログラムを簡略化し保守性を高められるという利点があります」と書いています。
しかし、ちょっとだけ不安に思うのが、簡略化し保守性を高めるためには、当然、DS2言語を理解して使いこなすことが前提なわけですよね。
複数人で仕事をする場合、運用保守のためには、メンバー全員が勉強しなきゃいけないわけですが、例えば今回僕が書いた、ごく初歩的な例にしても、理解するためには、通常のデータステップの知識とSQLの知識、ハッシュオブジェクトの知識、そしてさらにDS2言語の知識が必要になるわけです。
僕のような変態が、勝手に勉強して、勝手に変態コードを量産する分には問題ないですが、これをみんなで共有するためには、トレーニングが大変だなぁと。
SASを1から教えて、ここまで理解させようとすると、時間がかかりそう..。また逆に、ベテランで、既存のステップに何十年も慣れた人にとっても、これは抵抗あるかも。
まあ、そんなこと言っていては駄目ですね!!
海外のSASユーザーは、「新しい玩具だ!ヒャッハー!」みたいなノリで、どんどんDS2の情報を発信し始めてますね。
いつもSASの新機能への反応が鈍い日本ですが、今度は頑張って張り合ってみましょう。
僕も今日から勉強します。
もし既に、実務に応用されている方がいらっしゃれば教えてほしいです