少し回答が長くなりそうだったので、ここでお答えします。
まずいただいたコメントから
=================================================================================
匿名2014年1月22日 23:36
いつもブログを読んで勉強させてもらってます。現在自分が所属する部署ではSAS上でsort summary を行うことが多いため、そのための簡単なマクロを設定したいと思っています。sortではなくindexを設定する方が早いのでindexを活用していますが、index設定の際のキーが複数の場合と一つの場合の両方で使えるマクロは作成するのによいアイデアはありませんか?今の自分の知識では以下のマクロが精一杯です。
%macro sum(a,b,c,x,y);
/*
a ソートキー
bサムキー
c ソート項目が単数なら1
x インプットデータ
y アウトプットデータ
*/
%if &c=1 %then %do;
proc datasets nolist;
modify &x;
index delete &a;
index create &a;
run;
%end;
%if &c^=1 %then %do;
proc datasets nolist;
modify &x;
index delete keyZZZ;
index create keyZZZ(&a);
run;
%end;
proc summary data=&x noprint;
var &b;by &a;
output out =&y
sum=&b ;
run;
%mend sum;
=================================================================================
なるほど、僕はマクロはあまり上手ではないですが、とりあえず、cのパラメータ引数が少し無駄手な感じですね。
まず、サンプルデータセットを勝手に作ります
data Q1;
X='い';Y='A';Z=2;output;
X='い';Y='B';Z=3;output;
X='ろ';Y='A';Z=4;output;
X='い';Y='B';Z=1;output;
X='は';Y='A';Z=2;output;
X='ろ';Y='B';Z=5;output;
X='い';Y='A';Z=1;output;
X='は';Y='A';Z=2;output;
X='い';Y='B';Z=2;output;
run;
で、わかりやすい感じにするためやや冗長かもですが、以下の感じでしょうか??
とりあえず、引数1個減らしました。
options msglevel=i;
%macro sum2(a,b,x,y);
/*a:ソートキー bサムキー xインプットデータ yアウトプットデータ*/
%let c=%index(&a,%str( ));
proc datasets nolist;
modify &x;
index delete _all_;
%if &c=0 %then %do;
index create &a;
%end;
%if &c^=0 %then %do;
index create keyZZZ=(&a);
%end;
run;
proc summary data=&x;
var &b;
by &a;
output out =&y
sum=&b ;
run;
%mend sum2;
cで手動で1フラグをたてて、判定していた部分を、マクロ引数に半角スペースが含まれているか
どうかで判定させてみました。入っていれば複数変数が指定されているはず、と考えました。
どのインデックスがbyステートメントで採択されたかを明示するためoptions でmsglevelをiにしています。
元コードにあったdeleteは、元々設定されているインデックスを一度リセットする意図だと思うので
いっそ _all_で全殺ししました。
/*単一インデックスの実行例*/
%sum2(X,Z,Q1,A1)
/*複合インデックスの実行例*/
%sum2(X Y,Z,Q1,A1)
で、ふと思ったのが、ちょっと巨大なデータセット相手の経験が豊富ではないのでインデックスのパフォーマンスでの恩恵度合いが推定できないのですが、ソートかますと時間がかかり、それを飛ばすためだけにインデックスを使用してるということで、
summaryプロシジャでデータセットを作成するだけであれば
%macro sum3(a,b,x,y);
proc summary data=&x nway;
var &b;
class &a;
output out =&y
sum=&b ;
run;
%mend sum3;
/*実行例*/
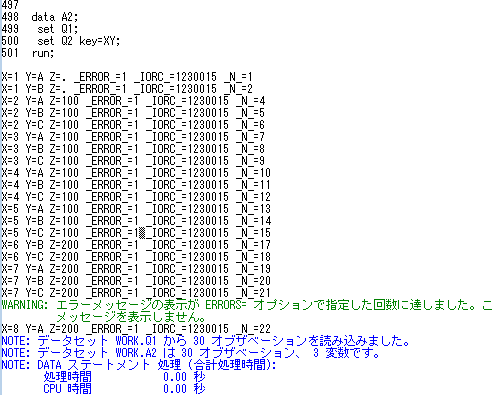
%sum3(X Y,Z,Q1,A2)
class ステートメントで今までbyで指定していた変数を指定してやれば、事前のソートも必要なく、単数でも複数でも可能で結果は同じになります。感覚的に、結構大きなソートされていないデータセットでもそこそこ早いような気がしてますが、どうなんでしょうか。
もしかしたら、的外れな回答、或いは既に知っていることを偉そうに能書いただけかもですが、その場合は申し訳ございません。
何かご質問ございましたら、どなたでもいつでもご連絡ください。
sasyupi@gmail.com