少し前に、ユーザー総会で発表するハッシュオブジェクトの前振りに、何個かコードを載せたところ、意外に反響があって、メールいただいたりしました。
基本から紹介して欲しいといったメッセージをいただいたので、できる範囲で少しずつやってみます。
我流で感覚的に勉強してきたので、きちんとした用語や正しい説明はできないと思いますのでご容赦ください。間違いもあるかと思うので、ガチで実践プログラムに入れる場合は、きちんと自分で検討検証してからにしてください。
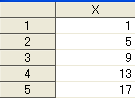
まず、ハッシュオブジェクトは乱暴にいうと、ルックアップテーブルです。KeyとDataという要素で成り立ってます。
構造的に、普通のSASデータセットをそのまま、ぶちこめる形をしているので、使い勝手がよいです。
また、ハードディスクではなく、メモリ上に展開されるため、そこからデータを出し入れするのが、鬼のように速いです。
例えばですが、Arrayステートメントで作成される配列は、要素番号という、いわば実データには存在しない「仮の番号」を付与することで、データを管理することをしています。
データの出し入れに際して、ユーザーは要素番号を指定することで、目的のデータにアクセスできるわけです。
脱線して超個人的かつ感覚的な話で、共感してくれる人は皆無だと思いますが、僕はそのことに、ずっと、SASで初めて配列を学んだ時から、疑問を感じてきました。
実際の世界にはどこにも1とか2とかいう要素番号はないのに、効率よく処理するために、1手間かけてわざわざ作成しているわけです。
将棋の「後手番一手損角換わり戦法」の発想と同じで、その後、効率よく進めるために敢えて手損をしているのです(個人的感想)。
それはそれで立派な戦法なのですが、どちらかというと変則的な戦法だと思うのです。もっと、より自然なやりかたはないのだろうかとずっと思っていました。
ハッシュオブジェクトは、KeyとDataという構造で、Key自体もデータであるわけです。つまり実際に存在するものだけを使って、そのままの形で、参照用のものを作っているわけです、
ユーザーはkeyと指定することで、それに紐づくdataにアクセスできるのです。
抽象的な話はこのへんまでにします。
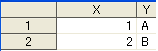
さて、以下に二つのデータッセットがあります。
data Q1;
X=1;Y='A';output;
X=2;Y='B';output;
X=1;Y='A';output;
X=2;Y='A';output;
X=3;Y='A';output;
run;
data Q2;
X=1;Y='A';Z='い';output;
X=2;Y='A';Z='ろ';output;
X=2;Y='B';Z='は';output;
run;
で、やりたいことは、Q1のデータッセットに対して、XとYをキーにしてQ2から
変数Zをひぱってくるという処理です。
SASやっている人なら、マージやSQLで反射的に書ける処理ですが、今回はハッシュ使います。
まずは、あと一歩のプログラムから
data A1;
if _N_=0 then set Q2;
if _N_=1 then do;
declare hash hq1(dataset:'Q2');
hq1.definekey('X','Y');
hq1.definedata('Z');
hq1.definedone();
end;
set Q1;
rc=hq1.find();
run;
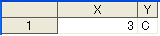
結果は
おしい!4オブザベーション目までは完ぺきなのに、5つめ
X=3、Y='A'の組み合わせはQ2には存在しないので、ここはnullになるはずなのに、
どこの値とってきとんねん!というところです。
(ネタばれすると、実は前のオブザベーションの値が引き延ばされている)
この5行目への対応は後で説明するとして、そこまでの処理を解説します。
まず、
①
if _N_=0 then set Q2;
これは、データセットQ2の変数情報を先に読み込ませておくための儀式です。
後ほどQ2の中身をハッシュオブジェクトの中にぶちこむんで、その後、データステップ中で
取り出すのですが、SASはハッシュオブジェクトの中身のことなんか知らないので、急にでてくるQ2にびっくりして処理をやめてしまいます。
具体的にいうと、PDV(プログラムデータベクトル)の外側から突如出現するZという変数に対して
「宣言されていないハッシュオブジェクトの data シンボル Z が、 行 177 カラム 4 にあります。
」とエラーを出してしまいます。
ので、いつもの、1オブザベーションも実行されないけど、データセットの情報は読み込んでます状態をつくりだすif _N_=0 then set ;を使っているわけです。
②
if _N_=1 then do;
これは、この後endまでの間に、ハッシュオブジェクトというものを作るのですが、1回作ればいいのです。そのままだと1オブザベーション読み込むごとに、毎回同じハッシュオブジェクトを再作成してしまい、余計遅くなります。
なのでこの条件をいれます。
③
declare hash hq1(dataset:'Q2');
declear hash の後に任意の名前をつけると、その名前でハッシュオブジェクトの作成が開始されます。この場合はhq1というのが、僕が勝手につけた名前です。
(dataset:'Q2')というのは、このハッシュオブジェクトの中にぶちこむデータはQ2から作りますよという指定です。実は、必ずしもデータセットから読み込まずに作れるので、ここは状況によって変わります。また、ここで使えるオプションも多くあるのですが、今回は紹介しません。
要注意なのは、シングルコーテーションを忘れがちなことです。
④
hq1.definekey('X','Y');
ハッシュオブジェクトには、メソッドという、予め決まっている方法でしか一切操作できません。
そしてメソッドは
ハッシュオブジェクト名.メソッド名(内容);の構造をとります。
つまり、ここでhq1.definekey('X','Y');としているのは hq1というハッシュオブジェクトに対して
definekeyメソッドを使い、内容は('X','Y')ということです。
でdefinekeyメソッドとは、その名の通り、ハッシュオブジェクトにキーを設定するメソッドです。
今回、Q2はXとYで一意になるので、それをキーにしています。
一意にならないのを指定するとエラーになります
(実はわざと一意にせずにエラーを回避して、それを利用する方法もあるが、いずれ)
⑤
hq1.definedata('Z');
definedataメソッドはデータを設定するメソッドです。今回、Zが欲しいのでデータはZです。
⑥
hq1.definedone();
definedoneメソッドを入れるまでハッシュオブジェクトの定義は完了しません。キー作って、データ作って、やること全部終わったら、忘れずにdefinedone
⑦
set Q1;
普通のデータステップです。Q1のデータをsetすれば、1オブザベーションずつ読み込まれて
outputされます。
⑧
rc=hq1.find();
rc=はリターンコード吸収用の割り当てステートメントです。SCL関数のところでもでてきましたね。
実はここだけじゃなくて、あらゆるメソッドにrc=とつけれます(名前はrcじゃなくてもよい)
で、ここに入る値は、メソッドがうまくいけばかならず0が入り、それ以外の場合、つまり何かしらメソッドにエラーが生じた場合は、そのエラーを示す数字が入ります。
hq1.find()はfindメソッドで、指定したハッシュオブジェクトのkeyとデータステップ中の同名の変数をマッチングして、マッチする場合、ハッシュオブジェクトのdataで指定されている値を全部もってきてくれます。
今回の場合ではQ1のXとYの値と、ハッシュオブジェクトのXとYの値を比較し、同じ場合はハッシュオブジェクトのZの値を持ってきてくれます。
ふ~、やっと説明終わり!
とはいかないのですね。5オブザベーション目ですね。。
そこのrcの値を見て下さい。0じゃないですよね、つまりfindメソッドは失敗した。
なぜ失敗したのか?マッチするキーがハッシュオブジェクトになかったから。
ハッシュオブジェクトはあくまでPDVの外側の世界なので、猪突猛進のSASデータステップは
我関せず、そのままZの値をretainし続けます。
そこで猪頭のSASに、わかる形で分岐条件を加えます。
rc=は割り当てステートメントでデータステップの世界に作られた値なので
ここは単純に
data A2;
if _N_=0 then set Q2;
if _N_=1 then do;
declare hash hq1(dataset:'Q2');
hq1.definekey('X','Y');
hq1.definedata('Z');
hq1.definedone();
end;
set Q1;
rc=hq1.find();
if rc^=0 then Z='';
run;
と最後にひとつ加えてやるだけで結果は
後はお好みでrcをドロップしてください。
やっと終わった。
ここまで読んで、なんて面倒なんだと思われたかもしれませんが、
慣れればすらすら書けます。
また続きはいずれ