以下のように
data Q1;
do X=8,2,4,7,1;
output;
end;
run;

data Q2;
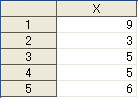
do X=9,3,5,5,6;
Y='A';
output;
end;
run;
という二つのデータセットがあったとします。
そこで
Q2の全ての値より小さいQ1のオブザベーションを抽出せよ。という問題が出たとします。
その場合、
proc sql noprint;
create table A1 as
select X
from Q1
where X<ALL(select X from Q2);
quit;
と書くことができます。
結果は

です。
ALLはこのように全ての値との比較を行うことができるキーワードです。
でも、恐らく多くの方がこう思われているはずです、最小値と比較すりゃええやん、と。
つまり
proc sql noprint;
create table A2 as
select X
from Q1
where X<(select min(X) from Q2);
quit;
ということで、結果は先のコードと全く同じです。
さて、ではALLと極値関数比較に違いはないのでしょうか?
あるんです。
先ほどのQ1と、新しく以下のデータセットQ3に対して同じ処理を考えます
data Q3;
do X=.,3,5,5,6;
Y='A';
output;
end;
run;

に対して
proc sql noprint;
create table A3 as
select X
from Q1
where X<ALL(select X from Q3);
create table A4 as
select X
from Q1
where X<(select min(X) from Q3);
quit;
とすると
ALLを使って作成したデータセットA3は

minを使って作成したA4は
です。
つまりALLでは、nullが入ったサブクエリ結果をとると、正しくできないので注意ということです。
whereでnullを省けば、作成可能です。
続いて、以下のコードではどうでしょうか
proc sql noprint;
create table A5 as
select X
from Q1
where X<ALL(select X from Q3 where Y='B');
create table A6 as
select X
from Q1
where X<(select min(X) from Q3 where Y='B');
quit;
Q3に対してwhere Y='B'としていますが、Q3のYの値は全て'A'なので、このサブクエリは空集合です。
さてこのように空集合が引数となった場合のALLの結果は

つまり、条件がかからずQ1がそのまま抽出されます。
対してmin関数で作成したA6については
です。
つまりALLと極値関数比較の違いは
★サブクエリ結果にnullが含まれる場合
ALL→×
極値→○
★サブクエリ結果そのものが空集合である場合
ALL→全オブザベーションがそのままでる
極値→×
といった感じなので、そこを踏まえて使いましょうということでした。




