僕はSASハッシュオブジェクトが大好きです。処理効率がいいとか、柔軟性が高いとか、コードの見通しがよくなるとか、マクロと相性いいとか、お勧めする理屈は僕なりに多々あります。
ただ個人的心情として、ぶっちゃけハッシュオブジェクトはコード書いてて面白いんですよね。
なんで面白いんかな?って考えると、既存のデータステップの枠を超えた処理がかけるので、想像力が試されてる気がして、それが刺激的なんですよね。
例えば、サンプルとして類型の多い有名なコードですが
data Q1;
X=1;Y=1;output;
X=1;Y=2;output;
X=1;Y=3;output;
X=2;Y=4;output;
X=2;Y=5;output;
X=3;Y=6;output;
X=3;Y=7;output;
run;

例えば、上記のようなデータセットを、Xの値で3つのデータセットに分ける場合、
data OUT1 OUT2 OUT3;
set Q1;
if X=1 then output OUT1;
if X=2 then output OUT2;
if X=3 then output OUT3;
run;
とかけます。
ルールとして、データステップ内でoutputされるデータセットはdataステートメントで指定されている
必要があります。
またOUT1 OUT2 OUT3としていますが、ここをXの値から取得して可変的に増減させることは
通常のステップでは難しいです。
恐らくマクロを使って、まずXの値のパターンをとって、データセット名を生成して、みたいな流れにせざるをえないはずです。
ところが、ハッシュオブジェクトだと
data _null_;
if _n_=1 then
do;
dcl hash hid (ordered:'Y', multidata:'Y');
hid.definekey ('X');
hid.definedata ('X','Y');
hid.definedone ();
end;
hid.clear();
do until (last.X);
set Q1;
by X;
hid.add();
end;
hid.output (dataset:cats('OUT',put(X, best.-L)));
run;
で結果は
【OUT1】

【OUT2】
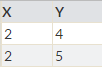
【OUT3】

となります。
かなり変態コードなので少し補足します。
まずDOWループの理屈を使って、by値のXごとにhid.clearとhid.outputが起きるようにしてます。
つまり、まずハッシュオブジェクトの中身をclearメソッドで空にして、by値のグループに対して処理をします。処理は単純にハッシュオブジェクトにそのグループのデータを追加していくだけの処理です。
その処理がおわったらoutputメソッドでデータセット化するわけですが、その時点のXの値を使って合成した文字列をデータセット名にしている。つまり動的に生成できてるわけです。
う~ん、心がいきいきしますね!楽しい!!
ただ、今回はわざと趣味でアクロバティックな例を出しましたが、本当はもっとわかりやすいものなので、わけわからんから業務に導入しない!という結論にならないようにお願いします!
0 件のコメント:
コメントを投稿