実際テストデータはまだ存在していないみたいな状況で、
動き始めなければならないことってあると思います。
下手すりゃ初めて実行するのが、
やっぱり作り手としては、データ無しで書けなくもないけど
ある程度、テストデータ使って、
例えば、
| 変数名 | 型 | 値リスト |
| sampleid | 数値 | |
| sex | 文字 | 男性/女性 |
| btype | 文字 | A型/B型/AB型/O型 |
| age | 数値 | 20-65 |
| ques1 | 数値 | 1,3,5,99 |
みたいなデータ定義書があって、
proc plan seed=1234;
factors sampleid = 100 ordered
sex = 1 of 2;
treatments btype = 4
age = 46
ques1 = 4;
output out= Q1
sampleid
sex cvals =('男性' '女性')
btype cvals =('A型' 'B型' 'AB型' 'O型')
age nvals =(20 to 65)
ques1 nvals =(1,3,5,99);
run;
quit;
とすれば
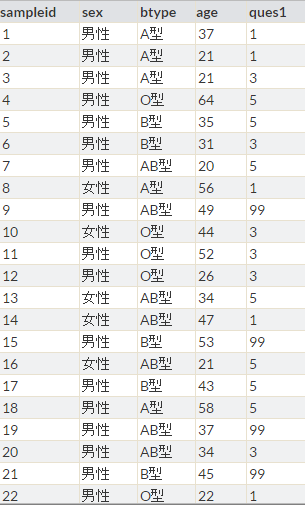
の通りです。
ちなみに各値の出現頻度は

のようカテゴリ数で大体等分されます。サンプル数少ないからちょっと綺麗になってませんが。
(発現割合をいじったりはこのやり方ではできないはず…)
もともと実験計画とか割付用の特殊なプロシジャを無理やりテスト
使っているのでステートメントに違和感がありますが、
サンプルID的な変数を指定しときます。
2変数以上指定しないと実行できないので、
後はtreatmentsで各変数のカテゴリ数、output=
文字数字を決めて、その発現リストを指定します。
上記の例は、1サンプル1オブザベーションのデータですが、
企業の売り上げデータが月ごとに積みあがっている以下のような場
| 変数名 | 型 | 値リスト |
| sampleid | 数値 | |
| month | 数値 | 1-12 |
| uriage | 数値 | 0-9999 |
であれば
proc plan seed=1234;
factors sampleid = 100 ordered
month = 12 ordered;
treatments uriage = 1001;
output out= Q2
sampleid
month nvals= (1 to 12)
uriage nvals=(0 to 9999)
;
run;
quit;

と先ほどsex = 1 of 2としていたところをmonth = 12というように
1 of を抜いてやればOKです。
あと、僕がよくやるのは、実際データって欠損が混じりますよね。
絶対入りませんと言われていたところが何故か本番で欠損だったこ
信用せずにID以外は全部ブランクが入る可能性があると考えてコ
なので
data _Q1;
set Q1;
call streaminit(1234);
array NV _numeric_;
do over NV;
if rand('uniform') <0.1 & vname(NV) NOTIN ('sampleid') then NV =.;
end;
array CV _character_;
do over CV;
if rand('uniform') <0.1 & vname(CV) NOTIN ('sampleid') then CV ='';
end;
run;

{kind=link}
0 件のコメント:
コメントを投稿