http://www.sinfonica.or.jp/tokei/graph/g62/index_l.html
なんか、結構ぐっときました。グラフ大事ですね。小学生とかが頑張って、手書きで棒グラフとか書いてんのに、プログラム回して一瞬でかける大人が、ついつい面倒くさがって描かないとか駄目ですね。
それに、別に小難しい凝ったグラフじゃなくて、本当に単純な棒グラフとか円グラフでも、立派に物事の本質を表現してますね。
というわけで、前フリとさほど関係ないんですが、ヒストグラムの細かい話します。
適当にデータ作ります。
data Q1;
call streaminit(777);
do i=1 to 200;
X=rand('normal',100,20);
output;
end;
run;
で、まずはunivariateプロシジャで描きますが、univariateプロシジャでhistorgam指定しても、要約統計量など、欲しいプロット以外のものもでてくるのでods selectを使います。ods select histogram;とすれば、histogramの名前を持つアウトプットしかでません。ただし、この命令は直後のプロシジャ出力にしか有効ではありません。今回は、ステートメントを調整しながらいくつも書くので、次のようにします。
ods select histogram(PRESIST);
proc univariate data=Q1;
histogram X /odstitle="デフォルト"
outhistogram=A1;
run;
proc univariate data=Q1;
histogram X / midpoints=(0 to 200 by 20) odstitle="Midpointsで中間点指定"
outhistogram=A2;
run;
proc univariate data=Q1;
histogram X / endpoints=(0 to 200 by 20) odstitle="Endpointsで終点指定"
outhistogram=A3;
run;
ods select ALL;
(PRESIST)をつけると、次のods selectが出るまで、その縛りが有効になります。
ods select ALL;でデフォルトの状態に戻ります。
さて、3つunivariateプロシジャを実行しました。
先に出力されたヒストグラムを確認してみます。

まず、何も余計なことしていない出力です。何も指定しないと、よきにはからえで、区間幅を決めてくれます。ヒストグラムの適切な区切りについては、色々あるのでリファレンス等を参照してください。(区間の取り方で、様子と与える印象が随分変わってしまうので、注意が必要です。)
注目なのは、目盛りの位置です。30にあって、次42なんですが、この場合、境界は36にあるんですね。24-36で一区間、36-48で一区間(ちょうど36がどっちに入るかは後で説明します)
このように境界値と境界値の間に目盛りがあるのは、midpointsという指定で、デフォルトがこちらです。
二つ目はmidpoints=(0 to 200 by 20)とした出力

このように全体の幅と、区間を指定することができます。
この場合、境界値はmidpointsで指定した値の間になります。
続いてendpoints=(0 to 200 by 20)です。midpointsとどこが違うか、注意深く目盛りを見てみましょう。

とこのように、指定した値そのものが境界値になってるわけですね!
ちなみに、実行後に
といったメッセージ(英語なのはUniversityだけかな?)がでる場合、データがプロットの範囲外にハミってるよという警告なので注意しましょう。
ちなみにNMIDPOINTS=、NENDPOINTS=というオプションもあって、そっち方は区間幅を指定しなくても区切りの数を指定することで、幅は自動で出してくれます。
さて実は3つのプロシジャに全てouthistogram=というものをつけていましたが、これはヒストグラムの情報をデータセット化したものを出力する機能になります。
3つそれぞれの結果を貼ります。



と、どの区間にどれだけのデータがあるか一目瞭然ですね。
オプションによって変数名が変わることに注意しましょう。
次ににsgplotでヒストグラムを書く場合
title "SGPLOTのデフォルト";
proc sgplot data=Q1;
histogram X / binwidth=20 binstart=0 showbins;
xaxis values=(0 to 200 by 20);
run;

binwidthで区間幅、binstartで、区間の開始点を指定し、全体の表示幅はxaxisで指定します。
で、見ての通りunivariateと同じでmidpints形式になっているのがわかります。
残念ながらsgplotにはendpointsに該当する指定がないので、どうにかやりたい場合は以下のようにスタート地点をずらします。
title "SGPLOTで強引にEndpoints表現";
proc sgplot data=Q1;
histogram X / binwidth=20 binstart=10 showbins;
xaxis values=(0 to 200 by 20);
run;

つづいて、
data Q2;
do X=2,3,4,6,8;
output;
end;
run;
といったデータセットがあったとします。
2種類の指定でunivariateを回すので
2 3 4 6 8という値で、3がどこの区間に含まれるかに注目してください。
ods select histogram(PRESIST);
title;
proc univariate data=Q2;
histogram X /odstitle="デフォルト";
run;
proc univariate data=Q2;
histogram X /odstitle="RTINCLUDE"
RTINCLUDE;
run;
ods select ALL;
まず、一つ目の出力は

境界値3が、どっちのバーに含まれてるかをみると、右側(大きいほう)ですね。
で、続いてRTINCLUDEをつけると

と、左側に入ります。
ちなみにSGPLOTの場合、
やはり何も指定しないと右側に組み込まれ
title "SGPLOTのデフォルトはboundry=upper";
proc sgplot data=Q2;
histogram X;
run;
title "SGPLOT boundry=lowwer";
proc sgplot data=Q2;
histogram X /boundry=lowwer;
run;
boundry=lowwerとすると左側に入ります。(画像は省略)
続いては、バーに、値をラベルとして表示する方法です。
その次にヒストグラムはunivariateでもsgplotでも、Y軸はパーセントがデフォルトですが、
それを度数に変更する方法も併せて実行してみます。
ods select histogram(PRESIST);
title;
proc univariate data=Q1;
histogram X /barlabel=percent odstitle="パーセントラベルの表示";
run;
proc univariate data=Q1;
histogram X /vscale=count barlabel=count odstitle="スケールを度数にしてラベルも度数で表示" ;
run;
ods select ALL;
まず一つ目の出力 barlabel=percentでパーセントの値を表示させます

続いて、2つ目、vscale=countで、Y軸の尺度を度数に変え、barlabel=countで表示するのも度数にしています。

SGPLOTで、尺度を度数にする場合は
title "SGPLOTでスケールを度数";
proc sgplot data=Q1;
histogram X/scale=count;
run;
とすると、
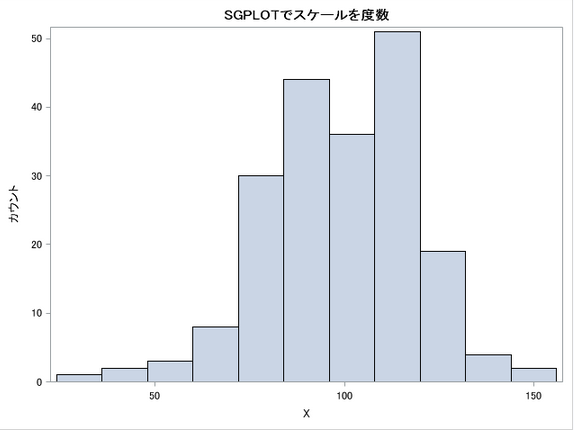
値の表示はどうするんだろう?ちょっとわかりませんでした。
もう疲れたんで、とりあえずここまで。どなたか教えてくれたらうれしいです。
=追記=
ちなみに最近勉強中のIMLでは
title;
proc iml;
use Q1;
read all var{X} into Q;
call Histogram(Q);
quit;
で

一緒ですね。詳細なオプションまではまだ手が回ってません。
最後に、実際よく使う、グループごとのヒストグラムを比較するようなグラフを作って終わりにします。ついでに正規分布曲線もはめときましょう。意味ないけど。
data Q3;
set Q1;
if _N_<=70 then GP='A';
else if _N_<=140 then GP='B';
else GP='C';
run;
ods select histogram(PRESIST);
title;
proc univariate data=Q3;
class GP;
histogram X /nrows=3 normal odstitle="classとnrowで並べて表示";
run;

0 件のコメント:
コメントを投稿