data Q1;
X=1;Y='A';output;
X=2;Y='B';output;
X=1;Y='A';output;
X=3;Y='B';output;
X=4;Y='C';output;
X=4;Y='C';output;
X=1;Y='C';output;
X=2;Y='A';output;
X=3;Y='C';output;
X=3;Y='A';output;
run;

そこから、Xについてのカウント集計のデータセット

Yについてのカウント集計データセット
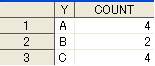
XとYの組み合わせについての集計

の3つを1ステップで作りたいとします。
え?そんなん、あのプロシジャで簡単に・・と思った人は、ちょっと黙っててください。
今回はハッシュ(反復子)オブジェクトでカウント集計をする方法を紹介します。
先にコードから
data DS_X(keep=X count)
DS_Y(keep=Y count)
DS_XY(keep=X Y count)
;
informat X Y COUNT;
if _n_ = 1 then do;
declare hash hx(suminc: "count", ordered: "yes");
declare hiter ix("hx");
hx.defineKey('X');
hx.definedone();
count = 1;
declare hash hy(suminc: "count", ordered: "yes");
declare hiter iy("hy");
hy.defineKey('Y');
hy.definedone();
count=1;
declare hash hxy(suminc: "count", ordered: "yes");
declare hiter ixy("hxy");
hxy.defineKey('X','Y');
hxy.definedone();
count=1;
end;
do while (^FL);
set Q1 end=FL;
rc=hx.ref();
rc=hy.ref();
rc=hxy.ref();
end;
rc=ix.first();
do while(rc=0);
rc=hx.sum(sum:count);
output DS_X;
rc=ix.next();
end;
rc = iy.first();
do while(rc=0);
rc=hy.sum(sum:count);
output DS_Y;
rc=iy.next();
end;
rc = ixy.first();
do while(rc=0);
rc=hxy.sum(sum:count);
output DS_XY;
rc=ixy.next();
end;
stop;
run;
長すぎ・・・・。
ただ、中身は部分、部分の繰り返しで、構造自体は非常に簡単です。
declare hash hx(suminc: "count", ordered: "yes");のsuminc:、
これは、ハッシュオブジェクトのキーが、何かしらのメソッドにおいて、参照されると
指定した変数の値が、キーごとに+1加算されていくものです。
それで
do while (^FL);
set Q1 end=FL;
rc=hx.ref();
rc=hy.ref();
rc=hxy.ref();
end;
の部分はrefメソッドで、キーがハッシュオブジェクトにすでに存在するかをチェックするcheckメソッドの機能に加えて、存在しない場合はそのままaddメソッドでハッシュにデータを追加するという多段階機能をもった便利メソッド。
もう読めたと思いますが、このrefメソッドによって、値の初回出現時にハッシュオブジェクトに追加されたデータが、続いて同じ値が出現した時にsumincの働きによって、カウンタが+1されていくという性質を使って、集計しているんですね。
そして最終的にsumメソッドで値を格納します。
そして最終的にsumメソッドで値を格納します。
集計条件分、ハッシュオブジェクトをつくり、ハッシュ反復子オブジェクトの全データをループで書きだすことにより、まるで1ステップ内で複数回のデータステップの処理を行っているような形にしているわけです。
さて、もうお気づきだと思いますが、今回の処理は普通にfreqプロシジャを使えば
proc freq data=Q1 noprint;
table X/out=DS_X(drop=percent);
table Y/out=DS_Y(drop=percent);
table X*Y/out=DS_XY(drop=percent);
run;
1ステップで終わるうえにたった5行です。
今回のケースに限っていえば、わざわざハッシュでやってたら、ちょっと、ご苦労様!って感じです。
実は、次の記事でこの仕組の応用例をやりたかったので、基礎の紹介としてやりたかっただけです。
ただ、こういった単純集計においても、場合によってはメリットが無いわけではないです。
例えば、infileなどでcsv等のデータを読み込んで、集計をする場合、freq等で集計するためには
まず、データセットを作成してから、そのデータセットに対してプロシジャ処理をかけなければならないので、どうあがいても2ステップかかります。
ところが今回の方法だと、1つのデータステップで、データの読み込みからダイレクトに集計結果のデータセットがつくれます。単純に読み込んだだけのデータセットが必要ない場合においては、有効です。
またfreqなどプロシジャは、複数の変数で集計はできますが、あくまで1回の実行につき、1つのデータセットが対象です。data=で複数のデータセット指定はできません。
ところが、ハッシュオブジェクトの場合は、ハッシュオブジェクトに突っ込んでから処理するので、流し込むデータセットが複数であっても1ステップでかけます。
またデータステップなので、途中で値の合成や、何かしらの処理を行って集計できます。
繰り返しの部分をうまくマクロにしたりすれば、すっきりかけます。
0 件のコメント:
コメントを投稿