例えば以下のようなデータがあるとします。
data EVENT;
begin=input('2014/01/05',yymmdd10.);output;
begin=input('2014/01/31',yymmdd10.);output;
begin=input('2014/02/01',yymmdd10.);output;
begin=input('2014/02/08',yymmdd10.);output;
begin=input('2014/02/25',yymmdd10.);output;
begin=input('2014/03/01',yymmdd10.);output;
begin=input('2014/03/05',yymmdd10.);output;
begin=input('2014/03/10',yymmdd10.);output;
begin=input('2014/03/14',yymmdd10.);output;
begin=input('2014/03/18',yymmdd10.);output;
format begin yymmdds10.;
run;
これはそうですね、例えば、ある会社と取引のあった日の履歴のデータだとします。
そして次に以下のデータセットを見てください。
data Q1;
ST=input('2014/01/01',yymmdd10.);EN=input('2014/01/15',yymmdd10.);output;
ST=input('2014/01/16',yymmdd10.);EN=input('2014/01/31',yymmdd10.);output;
ST=input('2014/02/01',yymmdd10.);EN=input('2014/02/15',yymmdd10.);output;
ST=input('2014/02/16',yymmdd10.);EN=input('2014/02/28',yymmdd10.);output;
ST=input('2014/03/01',yymmdd10.);EN=input('2014/03/15',yymmdd10.);output;
ST=input('2014/03/16',yymmdd10.);EN=input('2014/04/01',yymmdd10.);output;
format ST EN yymmdds10.;
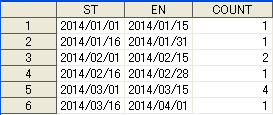
これは集計する対象区間を表しています。
この企業では、毎月、1日から15日まで、15日から月末までで区切って取引件数を集計している
としましょう。
さてQ1の各期間(STからEN)までの間に、データセットEVENTの日付がそれぞれ何回あるかをカウントするという問題です。
のような感じです。
さてさて、皆さんなら、どのようにして切り込みますか?
merge? transpose? sql? hash? array? formatとmeans?
多分、方法はたくさんあると思いますが、今回はintervaldsオプションとintck関数の
コラボで頑張ってみます。
で、早速コードなのですが、驚かないでください。
options intervalds=(event=work.EVENT);
data A1;
set Q1;
COUNT=intck('event',ST-1,EN);
format ST EN yymmdds10.;
run;
はい、なんとこれだけです。
これでさっきの求めるべきデータセットになります。
結構凄くないですか!
でも実はちょっとやりやすいように問題を作ってますので、そこも含めて説明します。
まずはintck関数を知らない場合、まずググってください。ちょっと説明が難しい関数です。
2つの日付(日時)データから、間隔を出すのですが、それが単純に日数差からの計算ではなく、例えば月の初日の開始時点を超えた回数、1月1日の開始時点を超えた回数で、間隔が何ヶ月だとか何年だとかって出します。
つまり、2007年12月31日と2008年1月1日をintck関数でyearを指定してだすと、1って出てきます。
2008年1月1日と2008年12月31日なら0です。
日数差で考えるとかたや1日、かたや364日ですが、重要なのはチェックポイントをまたいだかどうかなのです。
でoptions intervalds=(event=work.EVENT);はそのintck関数に使用するチェックポイントを自分で作成することができる方法なのです。
eventがユーザーがつける任意の名前で、あとでintck関数で指定します。
=でそのチェックポイント日時の入ったデータセットを指定します。
重要なのはここで起点日の変数名を必ず「begin」にしておくことです。なってないならrenameしましょう。
これが定義に必要な決まり文句、予約語になっています。
(ちなみにendという変数もつけれて、チェックポイントに幅をもたせれるのですが、またこんど)
もう一つ超重要なのが、beginの日付は必ず昇順になってないといけません!重複や、endを使う場合、区間の重なりも絶対ダメです。
エラーはでないけど、カウントがめちゃくちゃになるので、マジで危険です。
今回はソートしてませんが、必ずソートしておくことをお勧めします。
でCOUNT=intck('event',ST-1,EN); の部分です。
'event'の部分で、ユーザーが作成した任意の定義名を指定します。
ST-1としているのは、こうしとかないと、同日の場合にまたいだと見なされず、カウントされないからです。
どうでしょうか?このブログにしては割りと実用的な話だっと思います。
ただ、グループごとに処理する場合は使いにくいです。
例えば、臨床試験データなどで、被験者ごとにある注目している区間内に発生した、注目事象のカウントといったケースに適応しようとすると、被験者ごとにユーザー定義チェックポイントを作って、
被験者ごとに関数で指定しなきゃいけないわけです。
少数ならいいですが、データ数が多い場合は厳しいでしょう。処理時間も結構かかります。
またもう一つ、重要なのが、今回は強烈な前提条件として同日に複数レコード発生がないというものを置いています。通常の集計と違って、この方法は、チェックポイントのまたぎをカウントするので、同日に複数たっているとお手上げです。1件としてカウントします。それでいいなら逆に使えますが。