ベン図で書くと、上の黄色の部分です(ペイントで適当に書いたベン図なので、○の大きさが違う、、)
例えば
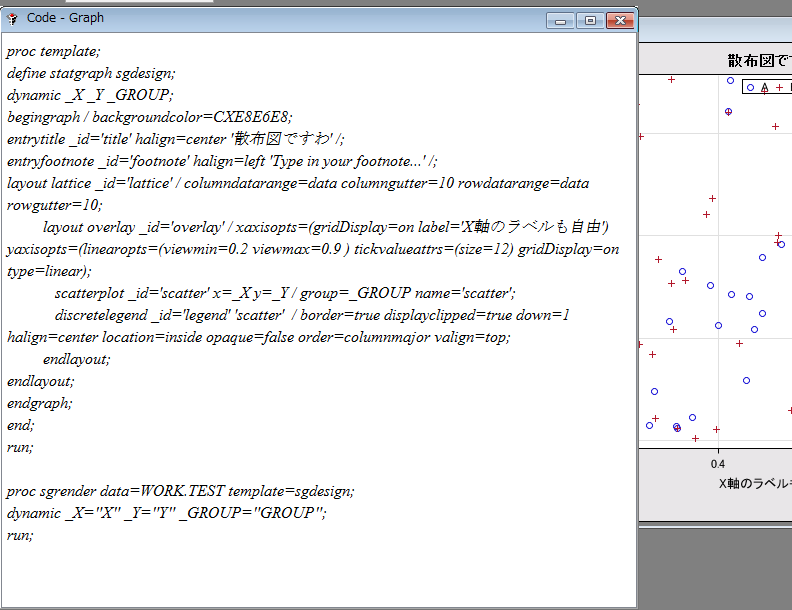
data Q1;
do X=1,3,4,6;
output;
end;
run;

data Q2;
do X=1,3,5,6,8;
output;
end;
run;

のようなデータセットがあった場合に1つのデータセットにしかないXの値をもった結果

を得るには、どんなコードを書けばいいでしょうか?
ただし、MergeステートメントとSQL両方のやり方で詰ませないといけないというのが
今回の問題です。
え?第一感楽勝!と思われるかもしれませんが、案外、つまづきませんか?
実際、このタイプの結合処理って、頻度少ない気がします。
大体は両方一致するものを残すか、片方を全部残して結びつくものを残す、いわゆる内部結合や片側外部結合が大半ですよね。
実は今回も自分の解答に自信がなくて、もし間違いや、抜け穴、最適じゃない書き方であれば
ご指摘いただけると助かります。
以下、(一応)解答
【MERGEの場合】
data A1;
merge Q1(in=ina)
Q2(in=inb);
by X;
if ^(ina*inb);
run;
こんな感じでしょうか?
ifのところは (ina=1 and inb=0) or (ina=0 and inb=1)みたいな感じでもいいですし
^(ina and inb)でも、ようはin=で指定した変数が全部1になるケースを除く書き方をしていれば
なんでもいいです。
【SQLの場合】
proc sql noprint;
create table A2 as
select coalesce(Q1.X,Q2.X) as X
from Q1 full outer join Q2
on Q1.X=Q2.X
where ^Q1.X | ^Q2.X;
quit;
こんな感じでしょうか?
完全外部結合がみそですね。
わかりやすくするために、create tableとりはずして
where句で Q1.X=0 or Q2.X=0 をしている部分も外しましょう(|はorを意味する記号)
proc sql;
select Q1.X label='Q1のX'
,Q2.X label='Q2のX'
from Q1 full outer join Q2
on Q1.X=Q2.X;
/* where ^Q1.X | ^Q2.X;*/
quit;
こうしたら

こうなるので、これをみれば、上のコードも理解しやすいはずです。
どっちかが欠測の場合を抽出しているんで、最初に見つけた欠測以外の値を取得する
coalesceが効いいるわけですね。
あ、ちなみに、僕が最初に思いついたSQLは
proc sql noprint;
create table A3 as
select X from Q1
union all corr
select X from Q2
except
select coalesce(Q1.X,Q2.X) as X
from Q1 innner join Q2 on Q1.X=Q2.X;
;
quit;
です。まあ、確かにベン図を表現していなくはない、気持ちはわからなくはないと思っていただければ浮かばれます。