今、以下のようなデータセットがあったとします。
data Q1;
X='ABCDE';output;
X='FGHIJ';output;
X='KLNMO';output;
X='PQRST';output;
X='UVWXY';output;
run;

①contains演算子
data A1;
set Q1;
where X contains 'K';
run;

これは○○を含むデータを抽出します。
上記の場合、Kという文字が、どこかに含まれて入れば抽出されます。
つまり
data A1_;
set Q1;
if index(X,'K')>0;
run;
と同じ意味になります。
②between演算子
data A2;
set Q1;
where X between 'K' and 'Z' ;
run;
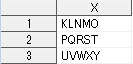
通常、数値に対して使用することが多いですが、文字変数に対しても適用できます。
between ○ and ×; で○と×を含んでその間に存在する値を抽出します。
今回は辞書を想像していただいて、KとZの間にある文字列が抽出されます。
③like演算子
data A3;
set Q1;
where X like '%I%' ;
run;

data A4;
set Q1;
where X like '_B_D%' ;
run;

likeの後に文字パターンを指定し、それに合致するものを抽出します。
%は0から無制限の長さの文字列です。like '%I%'は contains 'I'と同義です。
'_' ;は任意の1文字を表します。
一文字何かの後、Bがきてその後またなんでもいいので一文字きて、Dがきて、その後は何もなくてもいいし、どんな文字がどれだけきてもいいですから、そのパターンに一致するのを抽出してというのがwhere X like '_B_D%' ;ですね。
0 件のコメント:
コメントを投稿