Viyaとかでサポートしてる新しいCASエンジンだと,いろんなデータ型をサポートしてますが,ご存じ,SAS V9エンジンは,文字型と数値型の2本槍の漢仕様ですね
ところが,そんなV9さんも実はデータステップのセッション中に限りVARCHAR,可変長文字列をサポートすることができます
ステップが終了するとともに,従来の文字型(Char Type)に強制変換されますが,その辺ちょっと紹介
data A;
length x y z varchar(*);
x='A'; y='B'; z='あ';
run;
とすると可変長変数が作成できます

ログがなんかいうてますが,気にせず contentsにかけてみます
とすると可変長変数が作成できます
ログがなんかいうてますが,気にせず contentsにかけてみます
proc contents data=A;
run;
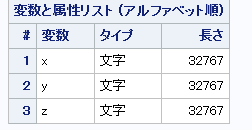
*を指定すると,文字型に戻った後32767のlengthになるようですね
そういや,ログでmsglevel=iつけろとか言うていたので,つけるとともに
アスタリスクではなくて10としてみると

で,だから,SAS9でほんのひととき,VARCHARにできたところで,なにが嬉しいの?
って話ですが
まず一つ目は,SAS忘備録の中の人に教えてもらった話
通常のSASの文字は固定長なので,よくある失敗ですが
||でつなぐと
そういや,ログでmsglevel=iつけろとか言うていたので,つけるとともに
アスタリスクではなくて10としてみると
options msglevel=i;
data B;
length x y z varchar(10);
x='A'; y='B'; z='あ';
run;
具体的に変換された変数を教えてくれました.INFOじゃなくてNOTEなんすね
proc contents data=B;
proc contents data=B;
run;

長さは20.
長さは20.
で,だから,SAS9でほんのひととき,VARCHARにできたところで,なにが嬉しいの?
って話ですが
まず一つ目は,SAS忘備録の中の人に教えてもらった話
通常のSASの文字は固定長なので,よくある失敗ですが
||でつなぐと
data C;
length X Y $10.;
x='A'; y='B'; ;
z=x || y;
run;

余計な空白が入りがちってやつですが
これが可変長であれば

このように,実際の長さに応じて調整が入るので,いちいちstripだなんだので空白除去が不要になる
あと,公式でちょっと面白いこと書いてて
https://documentation.sas.com/doc/ja/vdmmlcdc/8.1/nlsref/n01zuyhmhz32ufn1rajvb5xl4462.htm#p1gtkuek0ora5in1k39voups9j0g

へーー,どうやら,通常のSUBSTRやINDEXがVARCHAR型に対しては,KSUBSTR,KINDEXと同じ効用をもつようになるみたい.
早速実験
data A;

おー,ほんまや.通所の文字型に日本語入れてSUBSTRかけると文字化けするけど
VARCHARならKSUBSTRと同じように,文字単位で処理されてる
もしかすると,使い方によっては,活きてくるシチュエーションあるかもしれませんね
余計な空白が入りがちってやつですが
これが可変長であれば
data C;
length X Y varchar(10);
x='A'; y='B'; ;
z=x || y;
run;
このように,実際の長さに応じて調整が入るので,いちいちstripだなんだので空白除去が不要になる
あと,公式でちょっと面白いこと書いてて
https://documentation.sas.com/doc/ja/vdmmlcdc/8.1/nlsref/n01zuyhmhz32ufn1rajvb5xl4462.htm#p1gtkuek0ora5in1k39voups9j0g
へーー,どうやら,通常のSUBSTRやINDEXがVARCHAR型に対しては,KSUBSTR,KINDEXと同じ効用をもつようになるみたい.
早速実験
data A;
length x1 $10. x2 VARCHAR(10);
x1="あいうえお";
x2="あいうえお";
y1=substr(x1,1,1);
ky1=ksubstr(x1,1,1);
y2=substr(x2,1,1);
ky2=ksubstr(x2,1,1);
run;
おー,ほんまや.通所の文字型に日本語入れてSUBSTRかけると文字化けするけど
VARCHARならKSUBSTRと同じように,文字単位で処理されてる
もしかすると,使い方によっては,活きてくるシチュエーションあるかもしれませんね