非商用目的で 無料で使えるSAS OnDemand for Academicsについて,始め方がわからないという方は,あるいはインストール版のSAS9.4について,インストールの仕方にとまどうって方が多いということで,利用手順をスライドにしてアップしてくれた方がいるので紹介させてくださいませ
https://www.docswell.com/s/NorihiroSuzuki/KNLD4E-SAS_ODA_9.4_installguide#p1
非商用目的で 無料で使えるSAS OnDemand for Academicsについて,始め方がわからないという方は,あるいはインストール版のSAS9.4について,インストールの仕方にとまどうって方が多いということで,利用手順をスライドにしてアップしてくれた方がいるので紹介させてくださいませ
https://www.docswell.com/s/NorihiroSuzuki/KNLD4E-SAS_ODA_9.4_installguide#p1
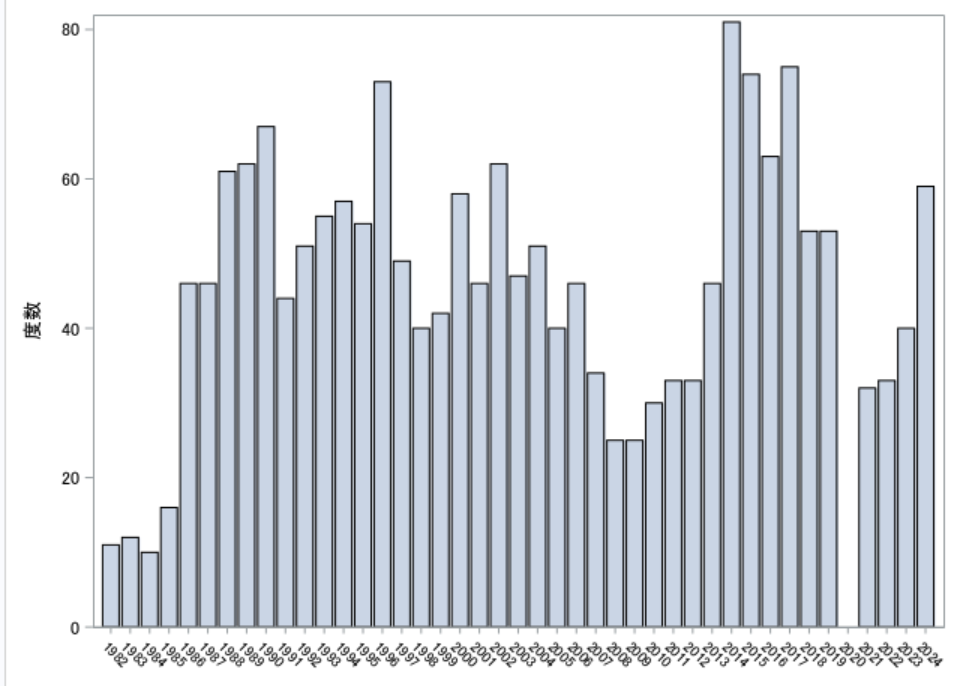
1982年~2024年までのSASユーザー総会論文集について,公開場所が分散していたりしていましたので世話人会のほうで一つ所にアーカイブしました
SASユーザー総会論文集アーカイブ
これは高橋 行雄 先生が2014年に当時の世話人会で行った,電子化・公開の取り組みを引き継いだものになります
目録のページには,全演題と,SAS社で公開されている発表スライドへのリンクをつけていってますが,確認しながら手作業でつけていっているので,まだ2000~2016年ぐらいまでです
また目録データはエクセルファイルでダウンロード可能です.
OCR由来なことと,名寄せ処理はおこなっておりませんが,簡単な分析はできると思います
エクセル取り込んでもらって
proc sgplot data=sugi;
where author_cat="筆頭筆者";
vbar year;
xaxis values=(1982 to 2024) valueattrs=(size=7);
run;
とかで 演題数の推移など
REGプロシジャにはCLASSステートメントがないため,カテゴリ変数をモデルに含める場合,事前に数値型でダミー変数を用意しないといけなかったり X*Yといった交互作用の記述をmodelステートメント内にかけないことから,例えば
data class1;
set sashelp.class;
sexn = choosen(whichc(sex,"男子","女子"),0,1);
age_height=age*height;;
run;
proc reg data=class1;
model weight = age height sexn age_height;
run;
quit;
などとして

proc hpreg data=sashelp.class;
class sex;
model weight = age height sex age*height;
run;
quit;

やっぱり モールス信号って業務で良く使いますよね.
プログラマ派遣先にいったら,全ての通信機器を取り上げられ,鉄格子窓のある部屋に閉じ込められて,SASの入ったPCだけ与えられて労働させられたみたいなあるあるの状況の際に
電気の消灯点灯タイミングで外部に助けを求めることができるかどうかが大事です
いちいち調べるの面倒なので,変換関数作ってみました
proc fcmp outlib=work.functions.common;
function text2morse (text $) $ ;
length key1 $1 text _rvalue rvalue $2000 ;
_text=upcase(compress(text));
declare dictionary d1 ;
d1["A"] = "・-";
d1["B"] = "-・・・";
d1["C"] = "-・-・";
d1["D"] = "-・・";
d1["E"] = "・";
d1["F"] = "・・-・";
d1["G"] = "--・";
d1["H"] = "・・・・";
d1["I"] = "・・";
d1["J"] = "・---";
d1["K"] = "-・-";
d1["L"] = "・-・・";
d1["M"] = "--";
d1["N"] = "-・";
d1["O"] = "---";
d1["P"] = "・--・";
d1["Q"] = "--・-";
d1["R"] = "・-・";
d1["S"] = "・・・";
d1["T"] = "-";
d1["U"] = "・・-";
d1["V"] = "・・・-";
d1["W"] = "・--";
d1["X"] = "-・・-";
d1["Y"] = "-・--";
d1["Z"] = "--・・";
do i = 1 to length(_text);
_key1=char(_text,i);
_rvalue= d1[_key1];
rvalue=catx(" ",rvalue,_rvalue);
end;
put _text= rvalue=;
return(rvalue);
endsub;
run;


data wk1;
SUBJID="AAA";AETERM="事象1"; AESTDY=1;AEENDY=5;output;
SUBJID="AAA";AETERM="事象2"; AESTDY=3;AEENDY=8;output;
SUBJID="BBB";AETERM="事象1"; AESTDY=2;AEENDY=30;output;
SUBJID="BBB";AETERM="事象2"; AESTDY=-2;AEENDY=3;output;
SUBJID="BBB";AETERM="事象3"; AESTDY=4;AEENDY=.;output;
SUBJID="CCC";AETERM="事象1"; AESTDY=15;AEENDY=20;output;
run;

proc sql noprint;
select min(min(AESTDY,1)) into:min trimmed from wk1;
select max(max(AESTDY,AEENDY)) into:max trimmed from wk1;
quit;
%put &=min;
%put &=max;
%let range =%eval( %sysfunc(range(&min,&max))+ (0<&min));
%put &=range;
data wk2;
set wk1;
array ar{&range.} $1.;
if &min < 1 then do;
st = AESTDY - &min + (AESTDY<1);
if ^missing(AEENDY) then en = AEENDY - &min + (AEENDY<1);
end;
else do;
st=AESTDY;
en=AEENDY;
end;
do i = 1 to ⦥
if st <=i <=en then ar{i}="Y";
else if st=i and missing(en) then ar{i}="Y";
else if st<=i and missing(en) then ar{i}="O";
end;
run;
%macro hed();
%do i = &min %to &max;
if &i ne 0 then ob.format_cell(data: "&i", style_attr: "background=blue color=white");
%end;
%mend;
%macro row();
%do i = 1 %to %eval(&range);
if ar&i="Y" then ob.format_cell(data: ar&i, style_attr: "background=red color=red");
else if ar&i="O" then ob.format_cell(data: ar&i, style_attr: "background=pink color=pink");
else ob.format_cell(data: ar&i, style_attr: "background=white color=white");
%end;
%mend;
ods excel options( sheet_name= "GANT" );
data _NULL_;
set wk2 end=EOF;
if _N_=1 then do;
dcl odsout ob();
ob.table_start();
*** header ;
ob.head_start();
ob.row_start();
ob.format_cell(data: "ID", style_attr: "background=darkblue color=white");
ob.format_cell(data: "Event", style_attr: "background=darkblue color=white");
ob.format_cell(data: "STDY", style_attr: "background=darkblue color=white");
ob.format_cell(data: "ENDY", style_attr: "background=darkblue color=white");
%hed();
ob.row_end();
ob.head_end();
end;
*** report ;
ob.row_start();
ob.format_cell(data: SUBJID);
ob.format_cell(data: AETERM);
ob.format_cell(data: AESTDY);
ob.format_cell(data: AEENDY);
%row();
ob.row_end();
if EOF then ob.table_end();
run;
ods excel close;
Proc OdstableはProc Reportでできる機能をほぼすべて実装可能なうえに,構文がよりシンプルであり,個人的には完全な上位互換だと思っています
ただ,RTFを作成する際の大きな弱点として,Proc ReportのbreakがOdstableにはなく任意の位置での改ページができないことがありました.
2018年にSASユーザー総会で「PROC ODSTABLEを用いた帳票作成」という論文が発表されていますが,そちらでもその点書かれていました.
8年間色々,チャレンジしてきましたが,最近また向き合う機会があり,一応実装できたので共有.
data output;
set sashelp.class;
if mod(_N_,3)=0 then break ="Y";
keep Name Age break;
run;
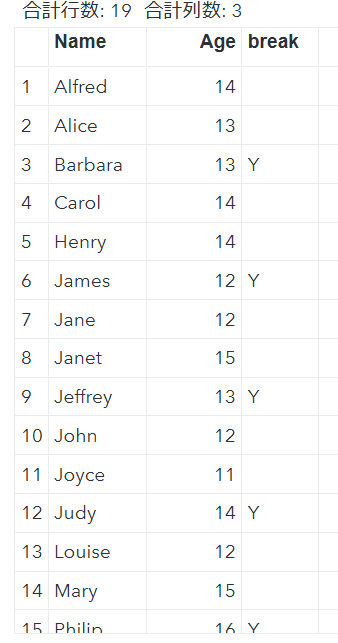
ods rtf ;
proc odstable data=output ;
column Name Age break ;
cellstyle break="Y" as data{PRETEXT="(*ESC*)R'\pagebb' " };
define Name; end;
define Age; end;
define break; print=no; end;
run;
ods rtf close;
なんとたったのこれだけで



まあ,医薬なら有害事象の持続とか,薬剤の継続使用を特定のカテゴリでまとめて
切れ間なく続いていた期間をまとめたレコードを合成するってことはあるのですが
これが結構SASだとやりにくい.SQLでもやれるんだけど,レコード一時的にかさむから
環境のパワーないとちょっと辛い時がある
なので結局,ハッシュオブジェクトを使ってしまう



