多分,SASのFREQに癖があるせいだと思うのですが,割合の95%信頼区間のSASでの処理がどうも苦手という相談を受けましたので
少しまとめました.
まず,基本的には 1症例1レコードで,対象となるイベントが起きたか起きてないかがY/Nや1/0で変数でもっているケースを考えます
オブザベーション数=解析対象集団の例数=分母 の状況です
data wk1;
SUBJID="001";FL1="Y";FL2="N";FL3="Y";;FL4="N";output;
SUBJID="002";FL1="N";FL2="N";FL3="Y";;FL4="N";output;
SUBJID="003";FL1="Y";FL2="Y";FL3="Y";;FL4="N";output;
SUBJID="004";FL1="N";FL2="N";FL3="Y";;FL4="N";output;
SUBJID="005";FL1="Y";FL2="N";FL3="Y";;FL4="N";output;
run;

オススメなのは,まずCLASSDATA集計してしまうことです.なぜかというと,YN両方の水準がそろっていないとFREQは計算ができないからです
なので
data clds;
if 0 then set wk1(keep=FL1 FL2 FL3 FL4);
do val ="Y","N";
FL1=val;
FL2=val;
FL3=val;
FL4=val;
output;
end;
stop;
drop val;
run;

そしてこれを使って集計します
proc summary data=wk1 classdata=clds;
class FL1 FL2 FL3 FL4;
ways 1;
output out=out1;
run;

👆
各変数 N,Yとそのカウント数が_FREQ_に入ります.summaryでways 1に絞ったのは,1水準ごとの結果しか必要ないからです
そして FREQプロシジャで
ods output BinomialCLs=out2;
proc freq data=out1;
table FL1 FL2 FL3 FL4/binomial(exact level="Y");
weight _FREQ_/zeros;
run;
とします
ここで binominalの中のexactはClopperpeasonと書いてもOK.大事なのはlevel=で見たい水準を必ず指定すること.そうじゃないと今回のNのように逆側の割合をとってしまうことがあるので.
そしてzerosオプションをつけないと0の場合の計算ができずにERRORになるので注意.
ods output BinomialCLs=out2;
により結果は
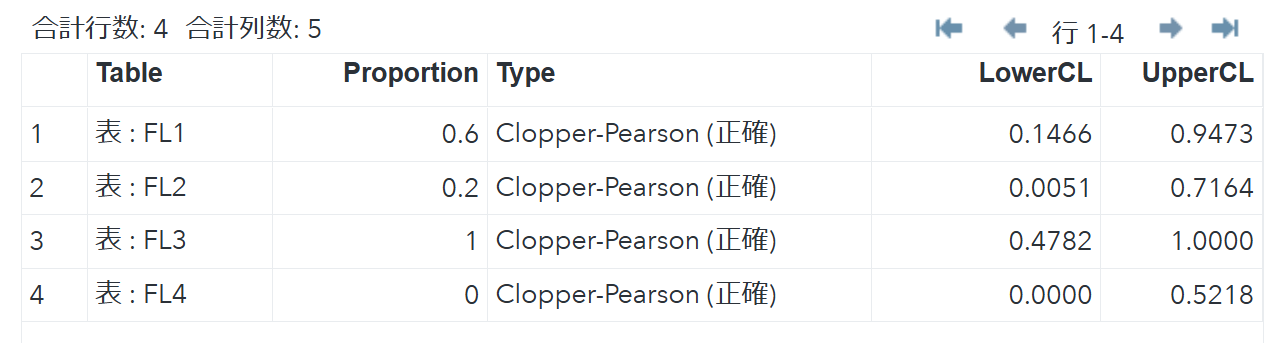
のようになります.
ods outputをつかわずに
ods output BinomialCLs=out2;
proc freq data=out1;
table FL1 FL2 FL3 FL4/binomial(exact level="Y");
weight _FREQ_/zeros;
output out=a binomial;
run;
とした場合,

👆
でるっちゃでるんですが,tableステートメントの複数指定には対応していないので,最後のもの(FL4)しかでていません.
なので,対象変数が1つの場合のみですね.そうでなければ ods outputがいいと思ってます
あとは適当に成形して
data result1;
length out1 - out3 $200.;
set out2;
out1 = strip(scan(Table,2,":"));
out2 = put( round(proportion * 100,0.1), 8.1 -L);
out3_1 = put( round(LowerCL * 100,0.1),8.1 -L);
out3_2 = put( round(UpperCL * 100,0.1), 8.1 -L);
out3 = cats("[",catx(", ",out3_1,out3_2),"]");
keep out1 out2 out3;
run;

みたいな.
で,次はADAEみたいに,全症例のYNではなくて,発生したイベントのみが積みあがってるデータについて考えてみます
data wk2;
length SUBJID AETERM $20. ;
SUBJID="001";AETERM="頭痛";output;
SUBJID="001";AETERM="腹痛";output;
SUBJID="002";AETERM="倦怠感";output;
SUBJID="002";AETERM="腹痛";output;
SUBJID="002";AETERM="頭痛";output;
SUBJID="003";AETERM="倦怠感";output;
SUBJID="003";AETERM="咳嗽";output;
SUBJID="003";AETERM="頭痛";output;
SUBJID="003";AETERM="腹痛";output;
SUBJID="004";AETERM="頭痛";output;
SUBJID="005";AETERM="頭痛";output;
run;

この場合,解析対象集団の全症例にレコードが起きてるわけではないので,別途,解析対象集団の例数(分母になるN)
を求めておき,マクロ変数等に入れておきます
/*解析対象集団のNが5の場合*/
%let Big_N=5;
で,集計したい軸で症例内の重複を除去して
proc sort data=wk2 out=_wk2 nodupkey;
by SUBJID AETERM;
run;

それを集計
proc summary data=_wk2 nway;
class AETERM;
output out=out3;
run;

あとは,データステップで計算してあげるだけです.
基本,Clopper-Pearsonの信頼区間の計算式はF分布使うのですが,F分布から変形して求められるベータ分布使うと計算式がグッと短くなるので
そっち使うのが一般的と思います
data result2;
set out3;
if 0 < &Big_N then per = round(divide(_FREQ_ , &Big_N) * 100,0.1);
if per=0 then CI_LOW=0;
if per=100 then CI_HIGH=100;
if per ne 0 then CI_LOW=round((1-betainv(.975,(&Big_N - _FREQ_+1),_FREQ_))*100, 0.1);
if per ne 100 then CI_HIGH=round((1-betainv(.025,(&Big_N - _FREQ_),_FREQ_+1))*100,0.1);
drop _TYPE_;
run;

F分布で計算すると
data result3;
set out3;
if 0 < &Big_N then per = round(divide(_FREQ_ , &Big_N) * 100,0.1);
if per=0 then CI_LOW=0;
if per=100 then CI_HIGH=100;
if per ne 0 then CI_LOW = round( (1+ (&Big_n - _FREQ_+1) / (_FREQ_ *finv(0.025, 2*_FREQ_, 2*(&Big_n-_FREQ_+1))))**-1*100,0.1);
if per ne 100 then CI_HIGH = round((1 + (&Big_n - _FREQ_) / (( _FREQ_ +1)*finv(0.975, 2*(_FREQ_ + 1), 2*(&Big_n - _FREQ_))))**-1*100,0.1);
drop _TYPE_;
run;

同じですね.